
یادگیری عمیق احتمالاً اصطلاح رایجی است که مدام میشنوید، در اینجا سعی میکنیم آن را به شیوهای بهتر توضیح دهیم، بنابراین دفعه بعد که در مورد آن سوال میشود، درک عمیقتری نسبت به آن خواهید داشت.
شما همیشه با دوستان خود صحبت میکنید، آن دوست دغدغهمند خاص که همیشه در مورد جنبشهای جهانی و امور جاری صحبت میکند. زمانی که تنها چیزی که میخواستید آرامش خاطر و مکانی برای کار با موبایل در جایی غیر از تختخواب بوده. به هر حال، شما تصمیم میگیرید با آن جستجو کنید، تعداد انگشت شماری از موضوعات را میبینید و روی موضوعاتی کلیک میکنید که به نظر میرسد اطلاعات مناسبی را ارائه میدهند.
شما میخوانید که چگونه گیاهخواری جان افراد را نجات میدهد و گوشتخواران چگونه به عذاب می افتند. "هیچ توهینی به ایالت کالیفرنیا نیست" وقتی که در صفحه اسکرول میکنید، تبلیغاتی را در کنار مقالات خود مشاهده میکنید و به طرز شگفت انگیزی شبیه کفشی است که یک ساعت پیش جستجو کردهاید. شما از خود میپرسید:
"آیا تلفن من میتواند ذهن مرا بخواند؟"
بله، میتواند و از همه عادتهای زشت و زننده شما مانند نحوه مسواک زدن بعد از دوش گرفتن آگاه است.
"این قطعا باید غیرقانونی باشد"
آرام باشید، در واقع نمیتواند. شرکتهایی مانند گوگل، فیسبوک و غیره از یادگیری ماشین و یادگیری عمیق برای ارائه نتایج بهتر برای جستجوهای شما استفاده میکنند، دادههایی را که جستجو کردهاید میگیرند، یک صفحه وب مشابه حاوی دادهها را جستجو میکنند و به شما ارائه میدهند.
اما موارد استفاده واقعی از یادگیری ماشین، یادگیری عمیق، هوش مصنوعی بسیار متفاوت است. با فرض اینکه تجربه قبلی در زمینه برنامهنویسی و کمی پایتون داشتهاید و کمی درباره یادگیری عمیق میدانید. مایلیم به شما کمک کنیم تا بفهمید که در حین انجام یادگیری ماشین در پشت صحنه چه میگذرد.
خوشبختانه در عصر حاضر، اطلاعات به آسانی در دسترس و یافتن آنها آسان است، به همین ترتیب، توسعهدهندگان استفاده از یادگیری عمیق را برای استفاده در کتابخانههای موجود در پایتون مانند scipy و scikit Learn بسیار ساده کردهاند. اما اگر میخواهید یک مسئلهی اساساً متفاوت را پیادهسازی کنید، مانند برداری که بتواند از یک شیب مشخص عبور کند و از موانع در طول مسیر جلوگیری کند، در کل به یک مسئلهی متفاوت تبدیل میشود. "این را به سختی آموختم". بنابراین برای درک کامل نحوه کار یک مدل یادگیری عمیق، شاید بتوانیم از ابتدا با استفاده از روش اصول اولیه، الگویی بسازیم.
حال با فرض دانستن اصول اولیه برنامهنویسی پایتون و برنامهنویسی شیگرا، این مسئله به یک مسئلهی بسیار ساده تبدیل میشود.
PERCEPTRON -1.1
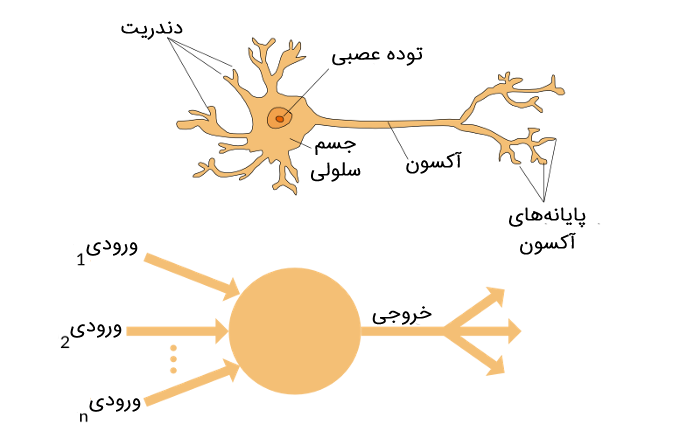
مانند transformer به نظر میرسد، بله اصلیترین عنصر اساسی بلوک سازندهی یک شبکهعصبی شبیه خواهر دوقلوی مگاترون (Megatron) به نظر میرسد. یادگیری عمیق در واقع همان فرآیند مشابهی را که از طریق آن، نورونهای مغز ما اطلاعات را پردازش میکنند، اطلاعات الکتروشیمیایی اعصاب مختلف بدن ما مانند اطلاعاتی مثل گرما، درد، حرکت و پردازش اعصاب و انتقال اطلاعات را تقلید میکند. به همین ترتیب، پرسپترون دارای ورودیهای مختلفی است که از طریق پرسپرترون در یک لوله (pipe) قرار گرفته و در آن یک تابع ریاضی اعمال میشود و یک خروجی میدهد.
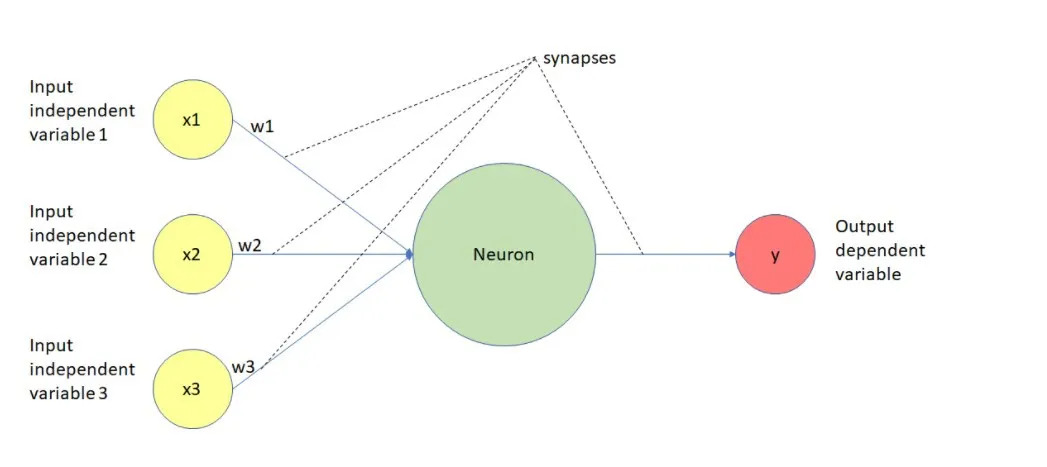
این یک نمایش واقعی از یک "نورون" در یک مدل یادگیری عمیق است.
نورون عمدتا سه کار انجام میدهد:
- دادهها را به عنوان ورودی میگیرد، در اینجا با نامهای x1، x2، x3 نشان داده شده است.
- ترتیبی از عملکردها را بر روی دادهها انجام میدهد.
- و در نهایت، خروجی را نمایش میدهد.
"نورون" ورودی را میگیرد، وزنهای مربوط به ورودیها را اضافه میکند، یک مقدار bias (بایاس) "b" اضافه میکند که قابل تغییر است اما مختص نورون است و خروجی را محاسبه میکند.
حالا، اگر به این سادگی بود، یادگیری عمیق یک تکه کیک بود، اما این فقط یک سطح است. این "نورونها" به هم متصل هستند و چیزی را ایجاد میکنند که شبکهعصبی نامیده میشود. این شبکههای عصبی میتوانند 100 یا حتی هزاران نورون را به هم متصل کرده و همه آنها دقیقاً همان کار را انجام دهند تا به نتیجه برسند.
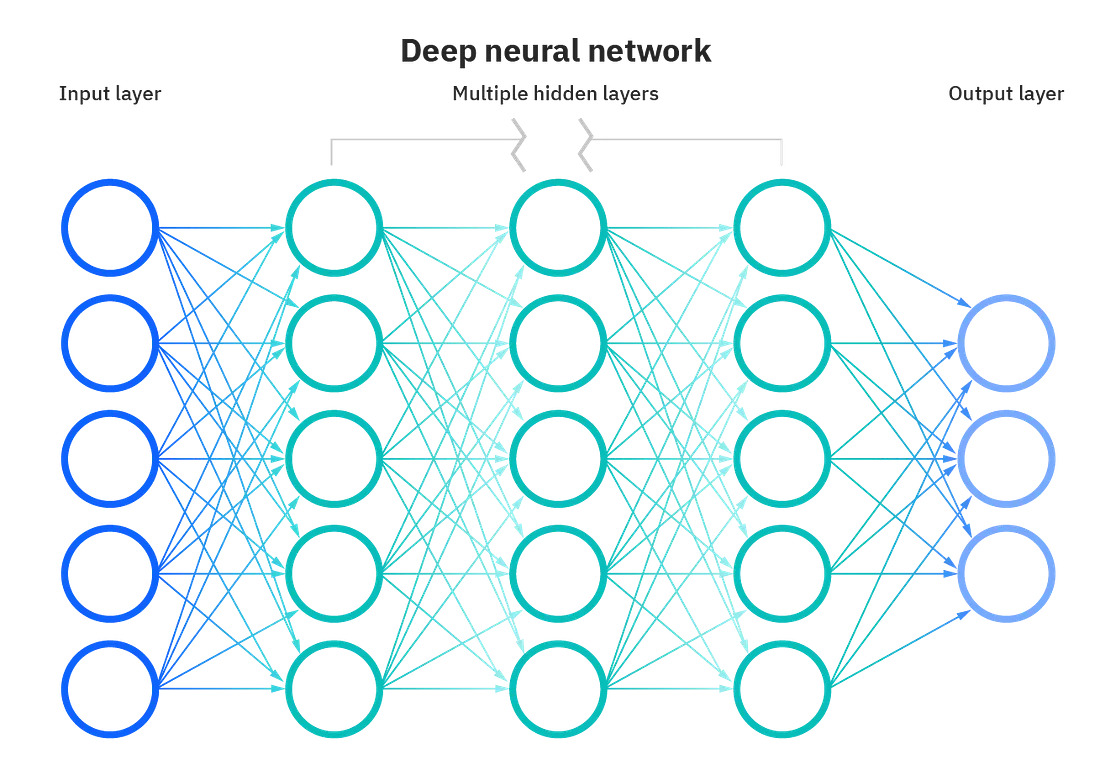
در اینجا هر "O" نشان دهنده یک پرسپترون است.
همانطور که میبینید، این بسیار پیچیده است "واقعاً امیدوارم این یک کلمه باشد".
اما وقتی آن را تجزیه میکنیم، درک آن بسیار آسان میشود. شما از نقش وزنها، بایاسها، توابع فعالسازی (Activation functions) و غیره پیروی خواهید کرد. اگر این کار شما را دوباره به همان حسی برساند که معلم ریاضی دبیرستان شما یک موضوع جدید را شروع کرده است، شما در جای مناسب هستید. نگران نباش زیاد سخت نیست.
1.2- درک پرسپترون
ما در واقع در اینجا برنامهنویسی میکنیم، من از Python 3.7 در Jupyter Notebook استفاده میکنم.
input = [1.2, 5.1,6.3]
weights = [2.3,5.6,9.3]
bias = 3
output = input[0] * weights[0]+input[1]*weights[1]+input[2]*weights[2] +bias
print(output)بیایید یک "نورون" را در اینجا در نظر بگیریم که ما 3 ورودی یعنی 1.2، 5.1، 6.1، وزنهای 2.3، 5.6، 9.3 و یک بایاس 3 داریم، اینها فقط اعداد تصادفی هستند که میتوانید با آنها بازی کنید و هر عددی را که دوست دارید انتخاب کنید. همانطور که میدانیم یک نورون ورودیها را میگیرد، وزن را چند برابر میکند و یک بایاس به آن اضافه کرده و یک خروجی میدهد. این نشان دهنده دقیق عملکرد یک نورون عصبی در سطح اساسی است.
1.3- کدنویسی یک لایه (Layer)
از آنجا که ما دیدیم که شبکهعصبی به طور واقعی یک شبکه از نورونها است. در این مرحله کاملاً واضح است. شبکهعصبی را میتوان به 3 لایه تقسیم کرد، لایه ورودی، لایههای مخفی و لایه خروجی. ورودی و خروجی کاملاً خود توضیحی هستند که مقادیر را به عنوان ورودی گرفته و مقدار خروجی را نمایش میدهند.
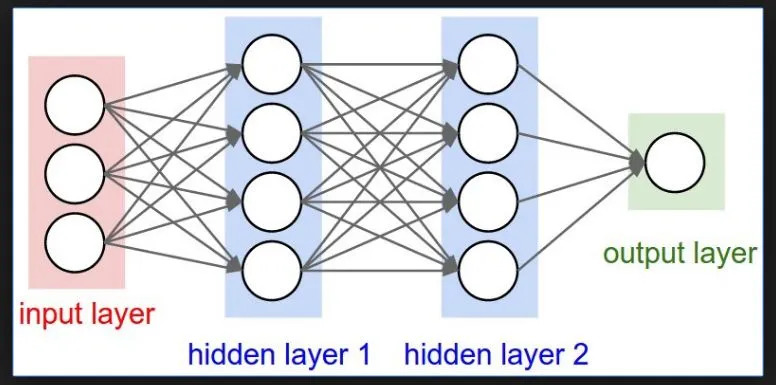
بیایید سعی کنیم این را در کد تجسم کنیم، در اینجا ما سعی میکنیم یک لایه را کدنویسی کنیم، ما فرض میکنیم که یک نورون را از "لایه پنهان 1" کدنویسی میکنیم، بنابراین به ورودیها، 3 وزن و همزمان 3 بایاس نیاز داریم و از نظر ریاضی همین قضیهی weights*inputs+bias اعمال میشود.
inputs = [1,2,3]
weights = [[2.6,5.6,1.3],[5.1,1.6,3.3],[1.2,5.4,6.3]]
biases =[2,3,5]
layer_output= [] #Output of the Current Layer
for neuron_weights, neuron_biases in zip(weights,biases):
neuron_output= 0
for n_input, weight in zip(inputs, neuron_weights):
neuron_output+= n_input*weight
neuron_output+= neuron_biases
layer_output.append(neuron_output)
print(layer_output)برای درک این موضوع باید مستقیماً صحبت کرد، در اینجا ما 3 ورودی، وزن و بایاس داریم که همه در یک لیست نشان داده شده است. به منظور پویاتر جلوه دادن از حلقهها استفاده کردیم، اما مفهوم همان است. هر لیست وزن در ورودی ضرب شده و بایاس مربوطه را اضافه میکند. این اساسیترین اصل نمایش یک لایه در یک شبکهعصبی است. در حقیقت، بیشتر ورودیها و وزنها همه از طریق ماتریس نشان داده میشوند. اما، خوشبختانه برای ما، Numpy یک کتابخانه بسیار مفید برای کمک به ضرب و نمایش ماتریسها است. بنابراین، به منظور کاهش مقدار کد اضافی، میتوانیم وزنها، بایاسها و ورودیها را به راحتی در قالب ماتریس نشان دهیم و از "نقطه" برای ضرب آنها استفاده کنیم.
1.4- ابعاد یک آرایه
اگر تا به حال از Tensorflow استفاده کردهاید یا قبلاً یادگیری عمیق را امتحان کردهاید، شایعترین خطا:
“AttributeError: incompatible shape for a non-contiguous array”
میباشد که به نظر من، این بیشتر از افرادی که آرام جلوی شما راه میروند، آزاردهنده است.
بنابراین برای درک عمیق یادگیریعمیق، باید کاملاً با ابعاد و اندازه یک بردار آشنا باشید.
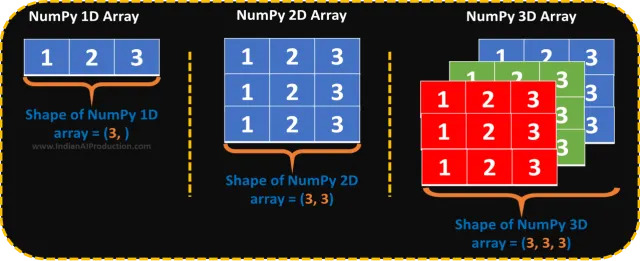
در اینجا یک صفحه تقلب lil وجود دارد، ابتدا ابعاد آرایه را که تعداد زیادی ورودی یعنی (x) — 1D، (x,y)- 2D، (x,y,z)- 3D و غیره را مشخص کنید، سپس تعداد عناصر موجود در سطرها و ستونها را مشاهده کرده و تعداد سطرها و ستونها را از چپ به راست به راحتی وارد کنید.
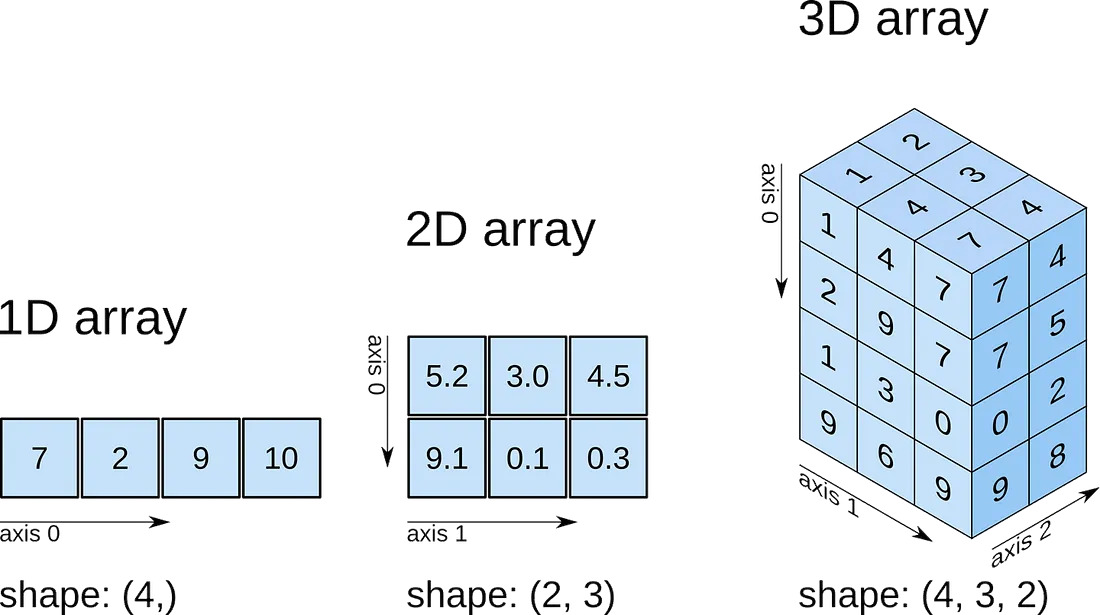
1.5- Dot Product
Dot Product اساساً ضرب یک سطر و ستون از یک بردار و افزودن مجموع به خروجی است.
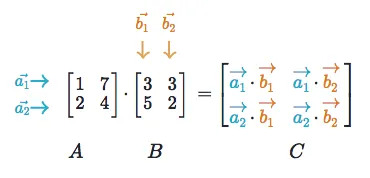
در کتابخانه numpy بصورت numpy.dot(a, b, out=None) نشان داده میشود، بنابراین باعث حذف کد اضافی میشود.
input = [1.2, 5.1,6.3]
weights = [2.3,5.6,9.3]
bias = 3
outputs = np.dot(weights, biases) + bias برای نورون دوم با 3 مجموعه وزن و بایاس
inputs = [1,2,3]
weights = [[2.6,5.6,1.3],[5.1,1.6,3.3],[1.2,5.4,6.3]]
biases =[2,3,5]
outputs = np.dot(inputs, weights) + biases
print(outputs)نمایش دادن بسیار آسان میشود.
1.5- دستهها (Batches)، لایهها (Layers)، اشیاء (Objects)
بسیار خب، ما با موفقیت کدنویسی و نمایش نورون الکترونیکی در یک شبکه را به طور ایدهآل انجام دادیم. در حال حاضر، این سوال پیش میآید که چگونه میتوان گروهی از نورونها را نشان داد که به هم متصل هستند. علاوه بر این، اکنون ما با مسئلهی چندین ورودی، با وزنهای متعدد و بایاسهای متعدد روبرو هستیم، "قسم میخورم آنقدرها هم که به نظر میرسد پیچیده نیست".
در حال حاضر، بیایید در واقع یک گام به عقب در جهت بزرگنمایی معنایی از مسئلهای که باید با آن روبرو شویم، برداریم. ما نورونهای ورودیای داریم که ورودی مجموعه دیگری از نورونهای لایه پنهان را که وزنها را ضرب میکنند و بایاسها را اضافه میکنند، فراهم میکنند و خروجی این، دوباره ورودی لایه دیگری از نورونهای پنهان است و دوباره خروجی آن لایه به لایه دیگری از نورونها وارد میشود، و همینطور تا رسیدن به خروجی. ما میتوانیم مجموعهای از ورودیها و خروجیها را به عنوان یک "دسته" (batch) گروهبندی کنیم که دقیقاً همان کاری است که انجام میدهیم، اساساً یک لایه را با دستهای از ورودیهای لایه قبلی تجزیه میکنیم.
راه دیگری که میتوانید به آن نگاه کنید این است که اساساً میخواهید از یک کوه صخرهای بالا بروید، در حالی که صخرههای سنگی در مسیر شما به سمت بالا هستند، اکنون یک برنامه در تلفن خود دارید که به شما نشان میدهد این صخرهها کجا هستند و در حال نزدیک شدن به آنها هستید. یک نقشه دقیقاً یک صخره را نشان میدهد که در فاصله 5 متری شما قرار دارد، در مقابل نقشه دیگری نیز هنگام نزدیک شدن به صخره، ده صخره را به شما نشان میدهد. کدام بهتر خواهد بود؟
شما بدیهی است که به سراغ ده صخره میروید، زیرا، راحتتر میدانید که کدام مسیر را بهتر است انتخاب کنید تا از این صخرهها جلوگیری کند.
به طور مشابه، عر چه ورودیهای بیشتری در اختیار نورون قرار دهید، نتیجه بهتر خواهد بود و باعث بهبود کارایی شبکه یادگیری عمیق میشود. در حال حاضر چندین هشدار وجود دارد که در ادامه توضیح بیشتری خواهیم داد.
دستهها و اندازه آنها، اجازه میدهد ورودیها را به "LOL" (لیستی از لیستها) که نشان دهندهی ورودیها است، تبدیل کنیم.
inputs = [[1,2,3, 2.5],[2,5,-1, 2],[-1.5,2.7,3.3,-0.8]]
weights = [[0.2,0.8,-0.5,1.0],[0.5,-0.91,0.26,-0.5],[-0.26,-0.27,0.17,0.87]]
biases= [2,3,0.5]
output = np.dot(inputs, np.array(weights)) + biases
print(output)به نظر میرسد که به راحتی میتوان "LOL" را با ورودیها و dot product ایجاد کرد. اما یک نکته وجود دارد "هیچ چیز به این سادگی نیست".
هنگام اجرای این قطعه کد، متوجه خطای بعد (shape) میشوید.
اما قبلاً کار میکرد، چرا اکنون کار نمیکند؟ اگر به مبانی dot product برگردید، میدانید که سطر با ستون دو بردار ضرب میشود. توجه داشته باشید که ورودیها دارای "3" سطر هستند، در حالی که وزنها دارای "4" ستون هستند، بنابراین سه عنصر در ستون ضرب میشود اما آخرین عنصر در ستونهای "4" ضرب نمیشود، زیرا هیچ عنصری وجود ندارد. بنابراین خطا ایجاد میشود.
نکته: "تعداد سطرهای ورودی اول dot product باید برابر با تعداد ستونهای ورودی دوم dot product باشد".
ابعاد آرایه وزنها 4*3 و ابعاد ماتریس ورودیها نیز 4*3 است، بنابراین برای سازگاری، ماتریس وزن باید ترانهاده (transpose) شود که به این منظور ستونها و سطرها باید جابجا شوند، این کار را میتوان به راحتی با استفاده از numpy و بصورت numpy.(array).T انجام داد. این را بر روی function ای که داریم اعمال میکنیم.
inputs = [[1,2,3, 2.5],[2,5,-1, 2],[-1.5,2.7,3.3,-0.8]]
weights = [[0.2,0.8,-0.5,1.0],[0.5,-0.91,0.26,-0.5],[-0.26,-0.27,0.17,0.87]]
biases= [2,3,0.5]
output = np.dot(inputs, np.array(weights).T) + biases
print(output)اکنون، ما یک لایه دیگر اضافه میکنیم تا همه اینها را انجام دهیم، مجموعهای دیگر از وزنها و بایاسها را اضافه کرده و خروجی لایه اول را ورودی لایه دوم قرار میدهیم.
inputs = [[1,2,3, 2.5],[2,5,-1, 2],[-1.5,2.7,3.3,-0.8]]
weights = [[0.2,0.8,-0.5,1.0],[0.5,-0.91,0.26,-0.5],[-0.26,-0.27,0.17,0.87]]
biases= [2,3,0.5]
weights2 = [[0.7,0.6,-0.5],[0.5,-0.51,-0.5],[-0.67,0.57,0.87]]
biases2= [-1,2,-0.5]
layer1_output = np.dot(inputs, np.array(weights).T) + biases
layer2_output = np.dot(layer1_output, np.array(weights2).T) + biases2
print(layer2_output)اکنون، ما با موفقیت دو لایه نورون را نشان دادیم.
1.6- تبدیل لایهها به Object ها
تاکنون، ما نمایش نورونها و عملکرد اصلی دو نورون به هم متصل را مشاهده کردیم. برای کاهش افزونگی و در واقع پویاتر شدن کد، میتوان مفاهیم برنامهنویسی شیگرا را معرفی کرد. ما میتوانیم نورونهای جداگانه را به object تبدیل کرده و مقادیری را برای آنها تعیین کنیم، و اساساً مشاهده عملکرد چندین نورون آسانتر میشود.
به طور معمول در نامگذاری یادگیری ماشین، ورودیها یا دادههای آموزشی (train data)، با نام "X" نشان داده میشود. بنابراین ابتدا باید با تغییر نام آن، شروع کنیم.
X = [[1,2,3, 2.5],[2,5,-1, 2],[-1.5,2.7,3.3,-0.8]]در مورد وزنها و بایاسها، وزنهایی که قبلاً آزمایش کرده بودیم در واقع نمیتوانند در مدلهای آموزشی واقعی استفاده شوند، زیرا وزنها بسیار بزرگ هستند، ضرب در ورودی و اضافه کردن بایاس و دوباره ضرب شدن و غیره، در نهایت خروجی بزرگتر و بزرگتر میشود و در نهایت منجر به انفجار داده میشود. ”تصور کنید که این را برای رئیس خود توضیح دهید”.
بنابراین، به منظور کاهش احتمال وقوع چنین اتفاقی، ما معمولاً از وزنهای کوچک به ترتیب 0.1 یا کمتر استفاده میکنیم. با در نظر گرفتن این موضوع، اجازه دهید یک کلاس با وزن، اشیاء بایاس و تابع ارسال به جلو (forward pass) ایجاد کنیم.
class Layer_Dense:
def __init__(self, n_inputs, n_neurons):
self.weights = 0.1 * np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
def forward(self, inputs):
self.output = np.dot(inputs, self.weights) + self.biasesدر کلاس Layer_Dense، دو آبجکت به نامهای Weights و Biases تعریف کردهایم. وزنها (weights) یک آرایه با مقداردهی تصادفی هستند که اندازه آن برابر با تعداد ورودیها ضربدر تعداد نورونهاست و سپس در 0.1 ضرب شدهاند تا مقادیر عددی کوچک نگه داشته شوند. بایاسها (biases) یک آرایه از صفرها هستند که بهصورت یک بردار سطری به اندازه تعداد نورونها ساخته شدهاند. این کار تضمین میکند که هیچ اختلاف اندازهای بین وزنها و بایاسها وجود نداشته باشد.
نکته دیگری که باید به آن توجه کرد این است که در ابتدا ضرب داخلی (dot product) به صورت «ورودی و ترانهادهی وزنها» تعریف شده بود، اما همانطور که در زمان مقداردهی اولیه وزنها مشاهده میشود، ما نمایش آن را تغییر دادهایم. قبلاً وزنها را به صورت n_neurons × n_inputs نمایش میدادیم. اما حالا که کنترل کامل روی مقداردهی اولیه داریم، استفاده از ترانهاده دوباره غیرضروری شده است.
اکنون میتوان خروجی را مشاهده و تجسم کرد.
X = [[1,2,3, 2.5],[2,5,-1, 2],[-1.5,2.7,3.3,-0.8]]
np.random.seed(0)
class Layer_Dense:
def __init__(self, n_inputs, n_neurons):
self.weights = 0.1 * np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
def forward(self, inputs):
self.output = np.dot(inputs, self.weights) + self.biases
layer1 = Layer_Dense(4,5)
layer2 = Layer_Dense(5,2)
layer1.forward(X)
#print(layer1.output)
layer2.forward(layer1.output)
print(layer2.output)این یک شبکه عصبی کامل است که با پایتون خام (core Python) پیادهسازی و تجسم شده است. اما کار اینجا تمام نمیشود؛ حالا باید بتوانیم این تابع را بهینه کنیم، هزینه (cost) آن را محاسبه کنیم و در ادامه بتوانیم وزنها و بایاسها را تنظیم کنیم تا یک نمایش دقیقتر و صحیحتر به دست آوریم.

مجتبی پاکزاد
حل مساله و چالش رو خیلی دوست دارم و رابطه خیلی خوبی با ریاضیات، برنامهنویسی و اقتصاد دارم. علاقه زیادی به هوشمصنوعی، یادگیری ماشین و موضوعات مرتبط دارم.
دیدگاهها
ثبت دیدگاه